
Prompt-Based Feature Engineering (Part 2) - What Is My Purpose? You Clean Data.
Or: Goodbye, Regular Expressions & Co, It Was Good While It Lasted!


Previously in this series: Part 1 - Generative AI Generates Data. Check it out here.
You clean data. I clean data. Everybody working with data cleans data. So far. While Generative AI and Large Language Models in particular are capable of many exciting things, they are unreasonably effective at the boring stuff. Before, we had to rely on deterministic functions to transform dates, process texts, and extract information. Now, we write a prompt and delegate the task to an LLM. Thanks to the probabilistic nature of LLMs and their resulting flexibility, we are able to do things that were previously considered impossible. Once you have seen this in action, there is a high chance you will never want to touch regular expressions, nltk, datetime, etc. ever again!
Set Up
We use gpt-3.5-turbo in combination with dpq. dpq is a python package for prompt-based feature engineering. All we need is an endpoint url, the API key and a model name to initialise the agent.
dpq_agent = dpq.Agent(
url="https://api.openai.com/v1/chat/completions",
api_key="YOUR_API_KEY",
model="gpt-3.5-turbo"
)Now let’s see explore what we can do with this. We start with a seemingly simple yet tricky task: cleaning city descriptions in a data set.
What is PlkjgsaRRRRRis?! (Answer: Paris)
Imagine you are given a data frame with a column containing statements about cities. You want to extract the city name and the mentioned attribute. How would we go about this? Typically, we would first split the words and find the name in a list of city names. For the attributes, we would then strip out uninformative words such as stop words. Now, imagine the data frame looks like this.

At this point, you might as well give up. What is PlkjgsaRRRRRis even supposed to be? Is this the worst OCR scan ever? For the fun of it, let’s use fuzzywuzzy to compute the Levenshtein Distance between this bit and an educated guess.
>>> from fuzzywuzzy import fuzz
>>> fuzz.ratio("PlkjgsaRRRRRis", "Paris")
42This quantifies what we already knew intuitively. Namely, the answer is 42. On a more serious note, finding a similarity threshold that works well in these situations will be tricky.
With this slightly artificial but familiar dread in mind, let's pass the data frame to the LLM and see how it handles the situation! The prompt we use is pretty simple.
"You only return the city mentioned."
Which we implement as follows using dpq.
messages = [
{
"role": "system",
"content": "You only return the city mentioned."
},
{
"role": "user",
"content": "I am in ro-------me"
},
{
"role": "assistant",
"content": "Rome"
},
]
# Add new function
dpq_agent.return_city = dpq_agent.generate_function(messages)We write a similar message to extract the attribute based on the following prompt.
"You only return the attribute used to describe a city."
Here is, what this looks like:
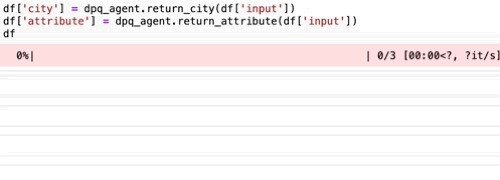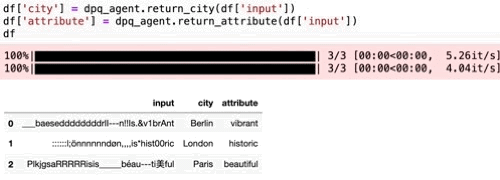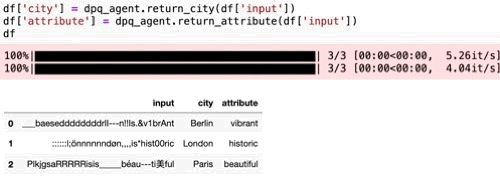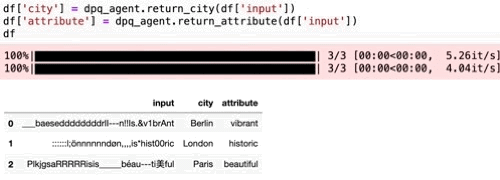
These two prompts do exactly what we wanted. Not only would this have been a lot of work before, accounting for all the potential noise in the input would have been close to impossible. Deterministic approaches are able to remove certain types of noise. Defining rules for every possible noise source, however, is impractical, especially as the data set grows larger. Since we are dealing with this probabilistically instead, we don’t have to: the LLM independently figures out the rules.
A Transformative* Experience
In the case of cleaning up misspellings, each word is roughly correct but hidden in the noise. Using LLMs, we can go one step further and transform data into entirely different, standardised formats. Let’s check out some typically headache-inducing examples that we can now handle.
Dates
One piece of data that is almost guaranteed to be consistently inconsistent are dates. They happen to be the bane of every data practitioner’s existence at some point. Here is an example causing Pandas datetime to throw an error.
>>> pd.to_datetime(['2024-W01-1', 'January the first, 2024'])
ParserError: Unknown string format: 2024-W01-1 present at position 0The first entry uses the ISO week date format. If the entire column used the same format, we could handle it using Python’s datetime package. The second entry, however, uses natural language to specify the date. Let’s ask the LLM to extract the dates from this column and return them in a pre-defined format. We use the below prompt.
"You return the given date in the format YYYY-MM-DD."
Which produces the following output.

Well, that worked. Note that this is a basic example and ignores all the amazing intricacies you might encounter when working with date and time formats like time zones, etc.
Phone Numbers
Similar to dates, phone numbers can come in a wide variety of formats for two reasons: there are many country specific differences and they tend to be free form input. Below is a quick example of transforming phone numbers. The prompt asks the LLM to follow the standard international formatting.

Convenient. To deal with phone numbers from different countries, you can combine the number and country information into one input string. For two Pandas data frame columns, we could do this as follows.
df['combined_input'] = df['number'] + ' from ' + df['country']We can then pass the combined input with an appropriate prompt to the LLM. This approach is of course not restricted to two columns and thus extremely flexible!
Standardise All the Things!
Before we wrap up, one more remark: dates and phone numbers are by far not the only bits of data that require standardisation. They are representative of a wide variety of information we usually need to process prior to any analysis. Further examples include addresses, spelling, units, and identifiers. In all these cases we need a common standard to allow for meaningful comparisons and aggregations.
You Swept Me Off My Feet, Mr. Robot.
In the second part of this series, we experienced the thrill of using LLMs for data cleaning. We have seen that LLMs have the potential not only to replace the current tool kit but to process data in ways that were previously impossible.
As mentioned in Part 1, however, we do need to be mindful of the limitations when using LLMs in practice. First and foremost, this means checking the output to detect hallucinations. These can have big implications for the robustness, reliability and reproducibility of our features. For instance, it is good practice to have metrics in place to evaluate our LLM-enhanced data pipelines. Alternatively, many data teams have started relying on an AI-as-a-judge approach.
The latter again represents the paradigm shift we have illustrated in this article: thanks to Generative AI, we move from deterministic to probabilistic data processing. While not perfect, this should make us very optimistic. It is the future the data community had hoped for: the machine is taking over one of the most time consuming aspects of our job, while we can focus on more interesting things.
In the upcoming parts of this series, we will move past data augmentation and cleaning to further explore how we can use LLMs to engineer features. In the meantime, feel free to add pull requests to the dpq repo on Github with prompts you have found useful!
*Yes, this is a triple pun.